We don't currently have a digital archive for the University of York but we are in the process of planning how we can best implement one. Myself and colleagues have been thinking about requirements and assessing systems and in particular looking at ways we might create a digital archive that interfaces with existing systems, automates as much of the digital preservation process as possible ....and is affordable.
My first point of call is normally the Open Archival Information System (OAIS) reference model. I regularly wheel out the image below in presentations and meetings because I always think it helps in focusing the mind and summarising what we are trying to achieve.
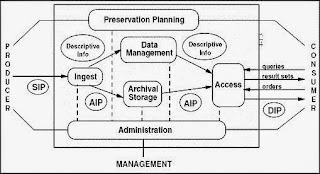 |
| OAIS Functional Entities (CCSDS 2002) |
From the start we have favoured a modular approach to a technical infrastructure to support digital archiving. There doesn't appear to be any single solution that "just does it all for us" and we are not keen to sweep away established systems that already carry out some of the required functionality.
We need to keep in mind the range of data management scenarios we have to support. As a university we have a huge quantity of digital data to manage and formal digital archiving of the type described in the OAIS reference model is not always necessary. We need an architecture that has the flexibility to support a range of different workflows depending on the retention periods or perceived value of the data that we are working with. All data is not born equal so it does not make sense to treat it all in the same way.
How we've approached this challenge is to look at the systems we have currently, find the gaps and work out how best to fill them. We also need to think about how we can get different systems to talk to each other in order to create the automated workflows that are so crucial to all of this working effectively.
Looking at the OAIS model, we already have a system to provide access to data with York Digital Library which is built using Fedora, we also have some of the data management functionality ticked with various systems to store descriptive metadata about our assets (both digital and physical). We have various ingest workflows in place to get content to us from the data producers. What we don't have currently is a system that manages the preservation planning side of digital archiving or a robust and secure method of providing archival storage for the long term.
This is where Archivematica and Arkivum could come in.
Archivematica is an open source digital archiving solution. In a nutshell, it takes a microservices approach to digital archiving, running several different tools as part of the ingest process to characterise and validate the files, extracting metadata, normalising data and packing the data up into an AIP which contains both the original files (unchanged), any derived or normalised versions of these files as appropriate and technical and preservation metadata to help people make sense of that data in the future. The metadata are captured as PREMIS and METS XML, two established standards for digital preservation that ensure the AIPs are self-documenting and system-independent. Archivematica is agnostic to the storage service that is used. It merely produces the AIP which can then be stored anywhere.
Arkivum is a bit perfect preservation solution. If you store your data with Arkivum they can guarantee that you will get that data back in the same condition it was in when you deposited it. They keep multiple copies of the data and carry out regular integrity checks to ensure they can fulfil this promise. Files are not characterised or migrated through different formats. This is all about archival storage. Arkivum is agnostic to the content. It will store any file that you wish to deposit.
There does seem to be a natural partnership between Archivematica and Arkivum - there is no overlap in functionality, and they both perform a key role within the OAIS model. In actual fact, even without integration, Archivematica and Arkivum can work together. Archivematica will happily pass AIPs through to to Arkivum, but with the integration we can make this work much better.
So, the new functionality includes the following features:
- Archivematica will let Arkivum know when there is an Archival Information Package (AIP) to ingest
- Once the Arkivum storage service receives the data from Archivematica it will check the size of the file received matches the expected file size
- A checksum will be calculated for the AIP in Arkivum and will be automatically compared against the checksum supplied by Archivematica. Using this, the system can accurately verify whether transfer has been successful
- Using the Archivematica dashboard it is possible to ascertain the status of the AIP within Arkivum to ensure that all required copies of the files have been created and it has been fully archived
I'm still testing this work and had to work hard to manage my own expectations. The integration doesn't actually do anything particularly visual or exciting, it is the sort of back-end stuff that you don't even notice when everything is working as it should. It is however good to know that these sorts of checks are going on behind the scenes, automating tasks that would otherwise have to be done by hand. It is the functionality that you don't see that is all important!
Getting systems such as these to work together well is key to building up a digital archiving solution and we hope that this is of interest and use to others within the digital preservation community.
Jenny Mitcham, Digital Archivist
.jpg)
.jpg)







